Ancestry: On the Vanguard of DevOps Security


(This is a guest post by Grant Johnson, Director, Risk & Compliance at Ancestry)
Over the past two years, Ancestry moved its entire applications and data infrastructure from local data centers to Amazon’s cloud, and this required a new approach for managing vulnerabilities in our DevOps pipeline. In the hopes that our insights will help security teams embarking on this path, this article details the challenges we faced and the best practices that helped us succeed, including:
- the benefits of replacing production AMIs with new ones instead of patching them;
- the importance of making security an enabler of agile, cloud processes like DevOps;
- and effective ways to get DevOps team members and senior leaders to buy into your risk reduction strategy.
Read on to learn how, with Qualys’ help, we streamlined and automated vulnerability fixes, resulting in a steep drop in the number of high severity bugs in our production applications.
Ancestry’s big bet on the cloud
In mid-2017, Ancestry made the decision to move the entire IT backbone to AWS. We needed a massively scalable, dynamic, and secure IT architecture to support the rapid growth of our business. We had amassed petabytes of data, and our business’ sharp seasonal fluctuations required instant bandwidth and computing resources to meet sudden spikes in website traffic. The plan was to be wholly cloud-based within about 18-20 months. We were all in and fully committed.
The effort was bold, given the scope of operations at Ancestry, the leader in family history and consumer genomics:
- 3+ million paying subscribers across 10 web properties
- 20+ billion digitized records
- 15 million people in the AncestryDNA network
- 100+ million family trees and 11 billion ancestor profiles
- 3 petabytes of data under management
With IT infrastructure moving to AWS, IT processes also got revamped. This included the adoption of DevOps practices for more nimble, iterative and collaborative software development and deployment. The IT priority was clear from the start: Support the benefits of our new AWS environment, such as speed, uptime reliability, economies of scale, and flexibility. Don’t implement anything that hinders the advantages of the cloud model.
For example, this meant treating our virtual servers “like cattle, and not pets”: IT needed the ability to take down virtual servers on a moment’s notice and duplicate them immediately. Thus, each stack had to be based on approved AMIs (Amazon Machine Images) and be rapidly deployable. We didn’t want any highly customized “snowflakes” in production.
The security strategy
Shifting to known AMI-based application deployment gave my team broad visibility into the security posture of our instances in AWS. At Ancestry, the security stakes are very high, in particular because we store people’s DNA information, which, as data goes, doesn’t get any more personal, sensitive and private.
![]()
With our new cloud-based model of constant code releases, and rapid server turnover, we decided to address new and existing vulnerabilities by adding the fixes to the upcoming AMI release and abandoned pushing individual patches to production. Our belief was that releasing a group of new, hardened AMIs would be more effective than trying to add patches to hundreds of existing production servers. Moreover, instead of adding patches and hot-fixes throughout the month, we’d ask our DevOps team to budget time in the scrum once a month for swapping in the new AMIs. We would only deviate from this plan for extremely critical vulnerabilities requiring emergency patching.
We also felt confident that by replacing our AMIs every 30 days, we’d be reducing the risk of undetected system compromises. In other words, we wanted to reduce the “dwell time” an attacker could have. Sophisticated intruders — the most dangerous — move slowly so that their actions don’t raise red flags. We would be reducing our attack surface by a constant flow of fresh and newly-hardened servers. We also bet that by focusing on production AMIs, the development teams would naturally update their production and stage environments to the new image without us requiring them to do so.
It took a little while for all of us — security, developers, IT ops staff — to get accustomed to this approach and cadence, and we didn’t immediately see the expected results. In fact, with the increased visibility into our expanding AWS instances, and the lagging, soon-to-be-retired servers, we initially saw vulnerability counts go up and up. On paper, our approach made sense, but it was taking a long time to show any evidence of success. We were under pressure to reduce the vulnerabilities that were rapidly being identified by our new scanning strategy and it just seemed to be getting worse. There were glimmers of data that would hint that the process was working, but overall trends continued to go in the wrong direction.
For example, one of the images that was released had to be immediately rolled back as it caused a production glitch. Admittedly, we had collective moments of doubt and even thought of scraping the process, but we stuck to our game plan, believing that over the long-term, it was the right approach. Going back to the idea of sending out spreadsheets and policing hundreds of individual patches just seemed like defeat.
Indeed, after a few months of steady adaptation to the new process of consistently swapping out AMIs every month and retiring scores of old servers, the process proved to be an astonishing success: In the course of a couple of weeks, vulnerability counts dropped sharply by about 80 percent. In fact, we initially suspected our scanning was somehow broken. It actually proved to be more effective than we had even imagined. Even more gratifying was that the process seemed to be sustainable. Hardening our servers just became a routine process that was baked into the day-to-day operations.
Our assumptions about the effectiveness and convenience of our approach outlined above all have proven true — aligning the vulnerability management process with the way IT and development teams operate in the cloud is actually working. Now we like to say that patching has become a curse word around here. It is all about the image. Think cattle, not pets.
A deeper technical look
We have a standardized set of about 9 different OS layer images consisting of Amazon Linux, Windows, and CentOS. We use Qualys to scan and update the new pool of images prior to release. Each new AMI includes all the security updates released in the past 30 days. We ensure the new image has no confirmed Severity 4 or Severy 5 vulnerabilities. Also key: Each image must include our Qualys credential so that we can perform deep, authenticated scans.
Once the new AMI is ready, we publish it and send developers and system owners an email asking that each system be updated within 30 days. An image that’s older than two months is considered non-compliant.
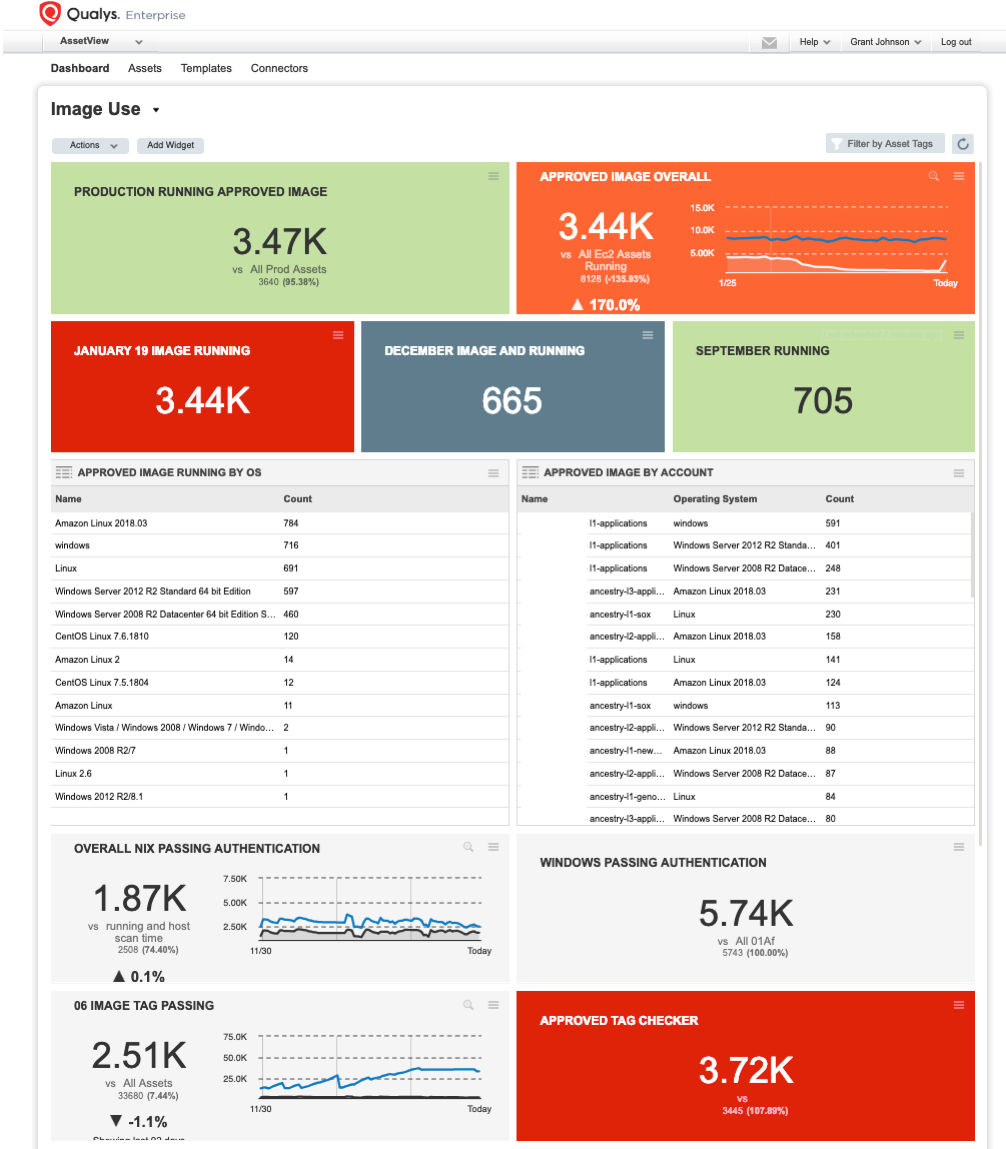
Qualys has played a pivotal role for us, even beyond the monthly creation of AMIs. We use Qualys to scan an ever-changing and expanding population of about 7,000 AWS servers each week. Moreover since the credentials were included in each of the images, and targeted only confirmed vulnerabilities, the data proved to be highly reliable.
We also publish the security posture of the AMIs and their patch compliance for every business unit as Qualys dashboards and send them reports periodically.
We also use Qualys to scan all our external IPs continuously, which is a must since Ancestry rolls out new code to the website constantly throughout the day: We need to know right away when a critical issue crops up.
Lessons learned
These practices have proven key to our success.
- We use AWS tags on the AMIs. To create a new stack, developers must provide owner, stackID, account group and other information — any system without a named owner gets shut down. This helps to track image usage and vulnerabilities on our Qualys dashboard. Tagging also simplifies our tracking of instance state, including identifying the ones that should be purged, and helps with generating Qualys reports.
- Beyond security, we also stressed our approach’s operational benefits, such as improved performance and reliability of the instances, which resonated with developers. If they are on the approved image, our ops team can tear down a bad host and spin another one up, usually without having to contact the developer.
- Early on, we sought support from our senior leadership, who always made it clear they stood behind our strategy. This helped get all the parties on board with the plan.
- We made authentication a priority up front. We insisted on adding scan authentication credentials directly to the new images from the beginning as we wanted our vulnerability information to be complete and accurate.
- We resist the urge to panic when new critical vulnerabilities are released in the wild, because we’re confident in the effectiveness of our process. Generally, we do not take any actions nor do we contact system owners when a vulnerability is released in the wild. So far, we’ve only felt justified in doing one out-of-band security patching in 11 months.
- We made it a point to not overwhelm the DevOps team with an avalanche of requests. That’s why we chose to require them to install the new AMI once a month in production environments specifically — not in the staging and sandbox environments as well, even though we are also scanning those every night.
(To learn more about Ancestry’s use of Qualys, please watch our video interview with Grant Johnson.)
More Qualys resources about DevOps:
Blog posts:
Assess Vulnerabilities, Misconfigurations in AWS Golden AMI Pipelines
DevSecOps: Practical Steps to Seamlessly Integrate Security into DevOps
Container Security Becomes a Priority for Enterprises
Infosec Teams Race To Secure DevOps
Securing the Hybrid Cloud: A Guide to Using Security Controls, Tools and Automation
Case studies:
Cisco Group Bakes Security into Web App Dev Process
Capital One: Building Security Into DevOps
White papers
Securing the Hybrid Cloud: Traditional vs. New Tools and Strategies