Qualys API Best Practices: KnowledgeBase API

This API Best Practices Series shows how to optimize your API usage starting with the KnowledgeBase API. The accompanying video presents these API best practices along with live code examples, so that you can effectively integrate the KnowledgeBase with other data and use it in process automation.
The Qualys API is a key component in the API-First model. From the beginning of Qualys in 1999, a rich set of Qualys APIs have been available and continue to improve. As a result, customers have been able to automate processing Qualys in new ways, increasing their return on investment (ROI), and improving overall mean time to remediate (MTTR) vulnerabilities throughout the enterprise.
Even with all these advances in API, some customers continue to experience suboptimal performance in various areas. Some challenges customers encounter with Qualys APIs are:
- Development: Where do I start with developing against the Qualys APIs?
- Design: Is my design using a best practices approach? Should I use the ETL design pattern?
- Performance: Is my API code optimized, and how do I know it is optimized?
At the end of this Qualys KnowledgeBase API blog post and video, you will gain experience in the areas of development, design, and performance with the Qualys API including:
- Applying a simple ETL design pattern to the KnowledgeBase API
- Live code examples demonstrating ETL of KnowledgeBase API
- Transformation of KnowledgeBase XML into J9\kid ySON
Definition of KnowledgeBase
Qualys KnowledgeBase: The industry’s largest number of vulnerability signatures, continuously updated by Qualys’ Research and Development team.
Software-as-a-Service (SaaS)
- Each day new and updated signatures are tested in Qualys’ own vulnerability labs and then published, making them available to Qualys customers.
- When Qualys Threat Protection is enabled for your subscription, the output will include Real-Time Threat Indicators (RTIs) associated with vulnerabilities.
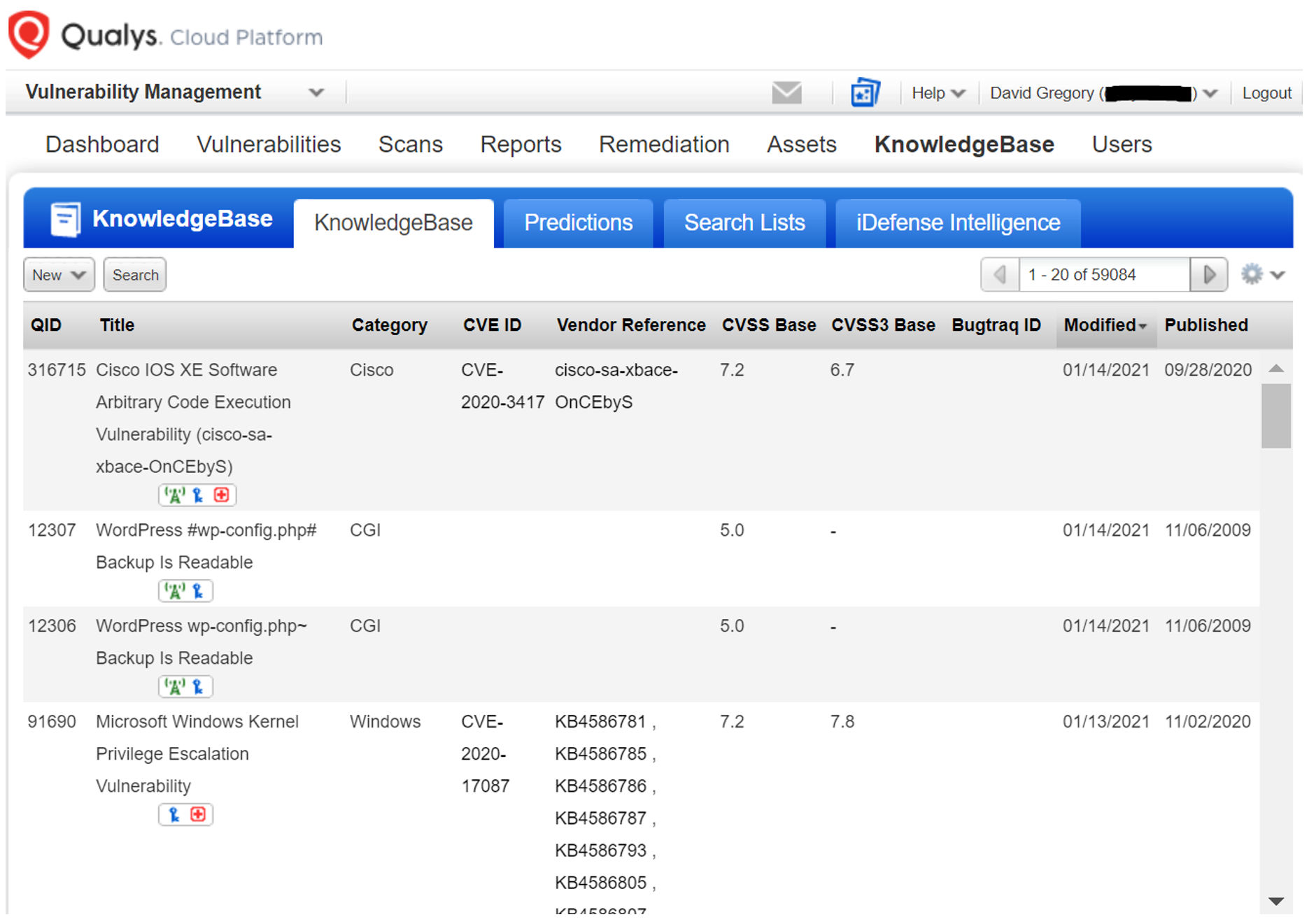
Automation Strategy
The Qualys API provides customers a way to consume your Qualys data, pulling it from the Qualys Cloud Platform to your site for consumption. A key part of that automation strategy includes downloading the Qualys KnowledgeBase, as it includes extensive details on threats and their corresponding solutions.
Customers can consume Qualys data for automated processing of:
- Vulnerability Analysis
- Metrics
- Operational Response
Automation Challenges
With any API, there are inherent automation challenges. Some of those automation challenges are:
- What are the best practice programming methods to extract a list of vulnerabilities from Qualys KnowledgeBase reliably and efficiently.
- How to obtain all KnowledgeBase XML output which provides a rich information source for each vulnerability.
- How to integrate Qualys data into customer database for reuse in automation.
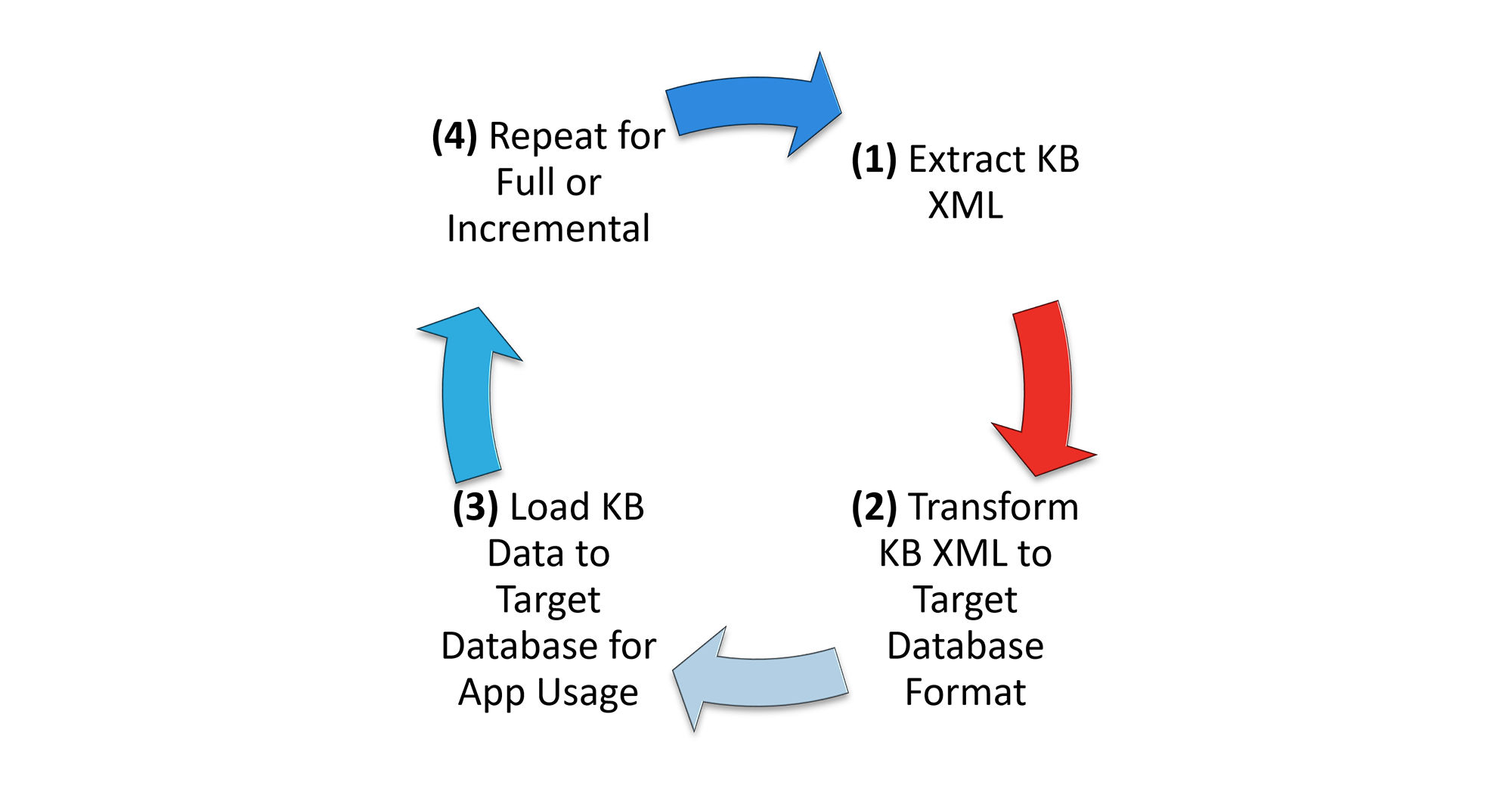
ETL Design Pattern
The ETL (Extract, Transform and Load) design pattern is a wonderful place to start when transforming Qualys API data into a form/format that is appropriate for your organization. In the video, we will walk through the ETL Activity Diagram and demonstrate live code examples to ETL your data into a local Python database.
Recommendation – Follow a basic ETL Design Pattern to prepare KnowledgeBase Data for Application Usage.
- Extract: Full or Incremental
- Transform: Prepare Data
- Load: Persistent Data Store
- Repeat: Update as Needed
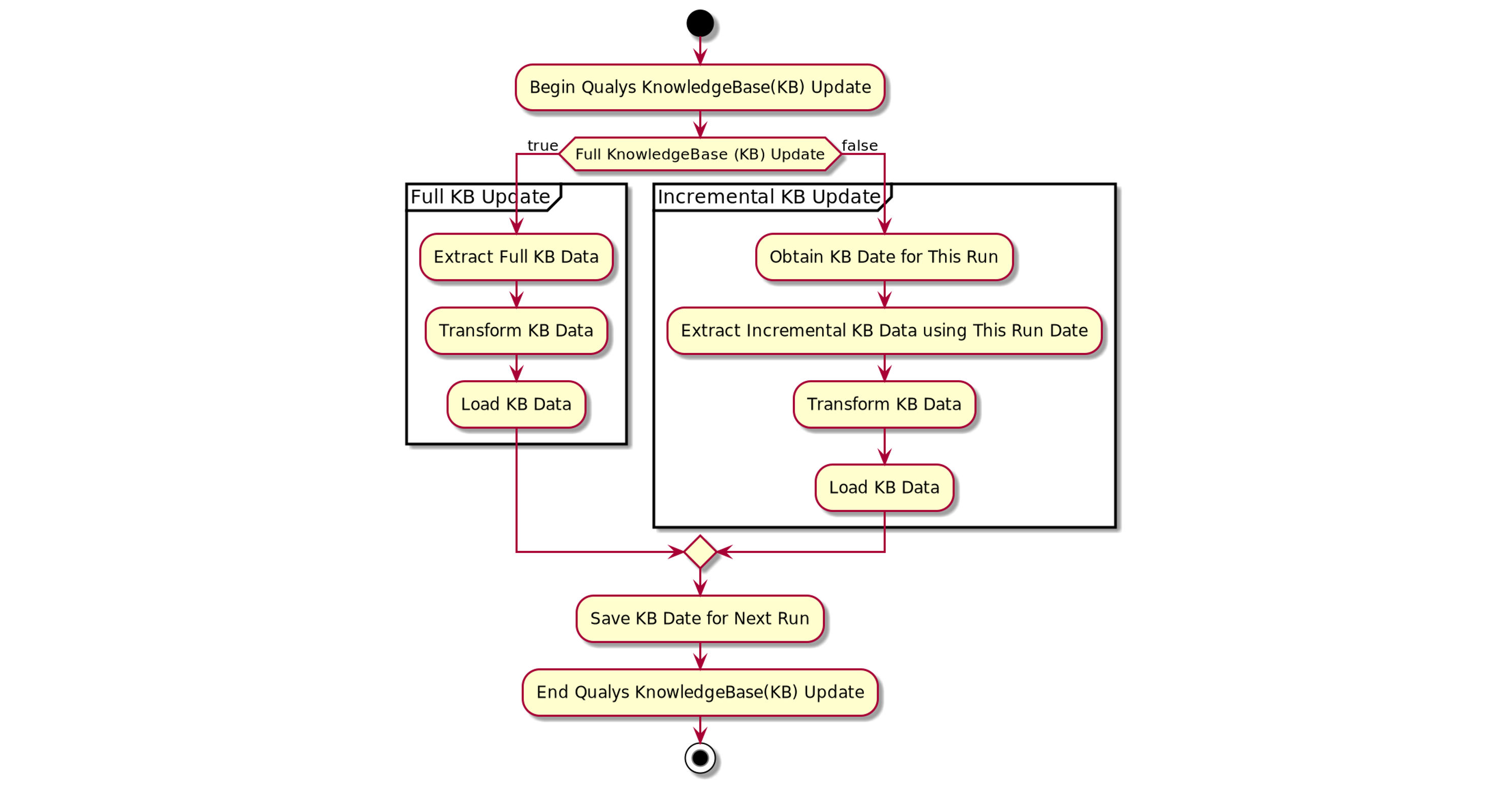
KB Activity Diagram
The key point of the KB Activity Diagram is to show there are two types of extracts. The first is a full extract. That will be your first run or in some instances, you may want to ensure you have all the KnowledgeBase data in your database after an outage or error. The second is the incremental update. That will be your primary way of pulling Qualys KnowledgeBase Data. With the incremental update, you speed up processing by eliminating duplicate data from being both downloaded and further evaluated for storage. This streamlines your processing and ensures the KnowledgeBase updates are ready for consumption by your applications as quickly as possible.
Recommendations:
- Store KnowledgeBase data local to your applications to improve performance.
- Improve performance and reduce duplicate data by performing full updates no more than once per month.
- Perform incremental updates in line with the Host List Detection download.
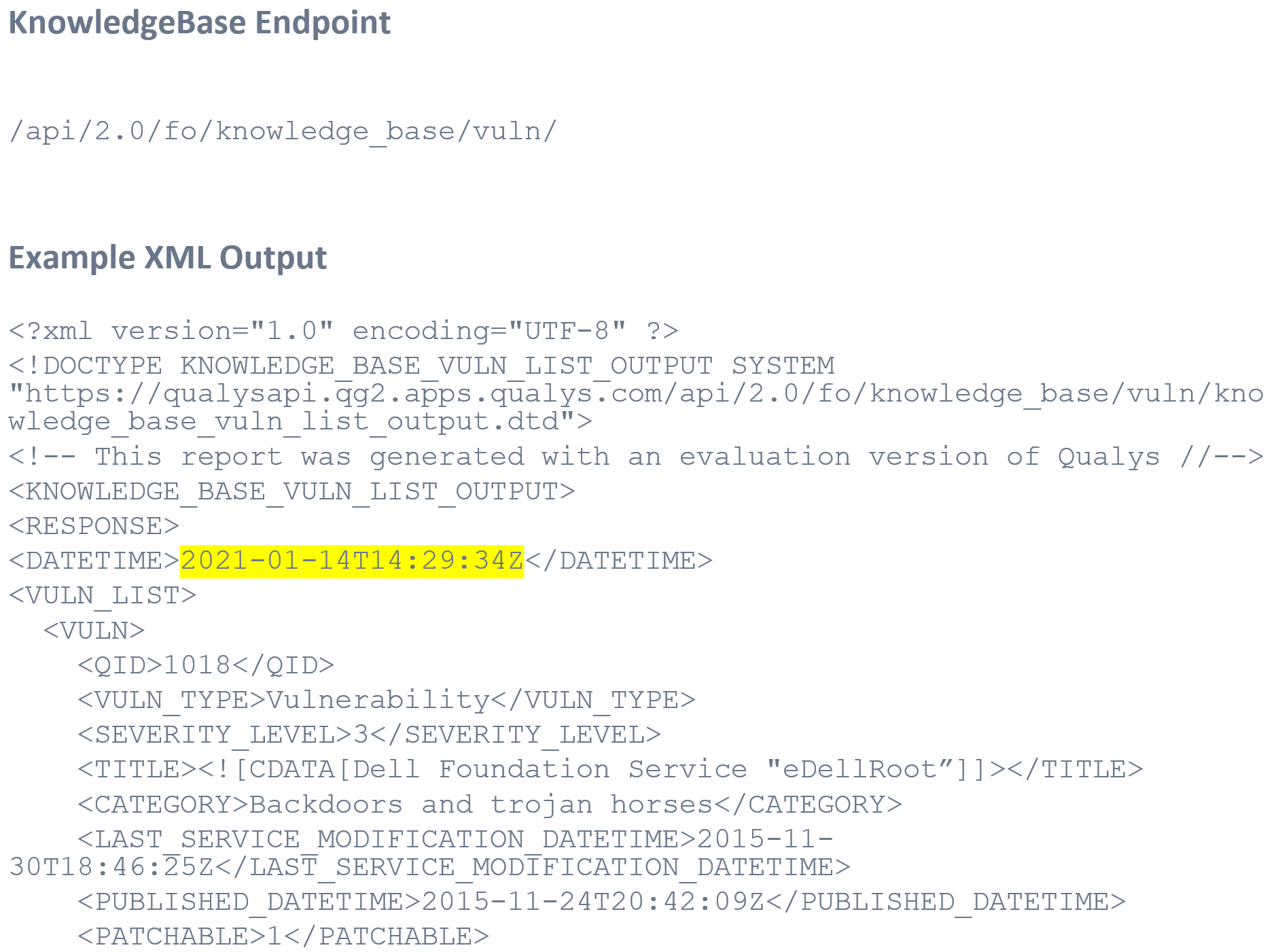
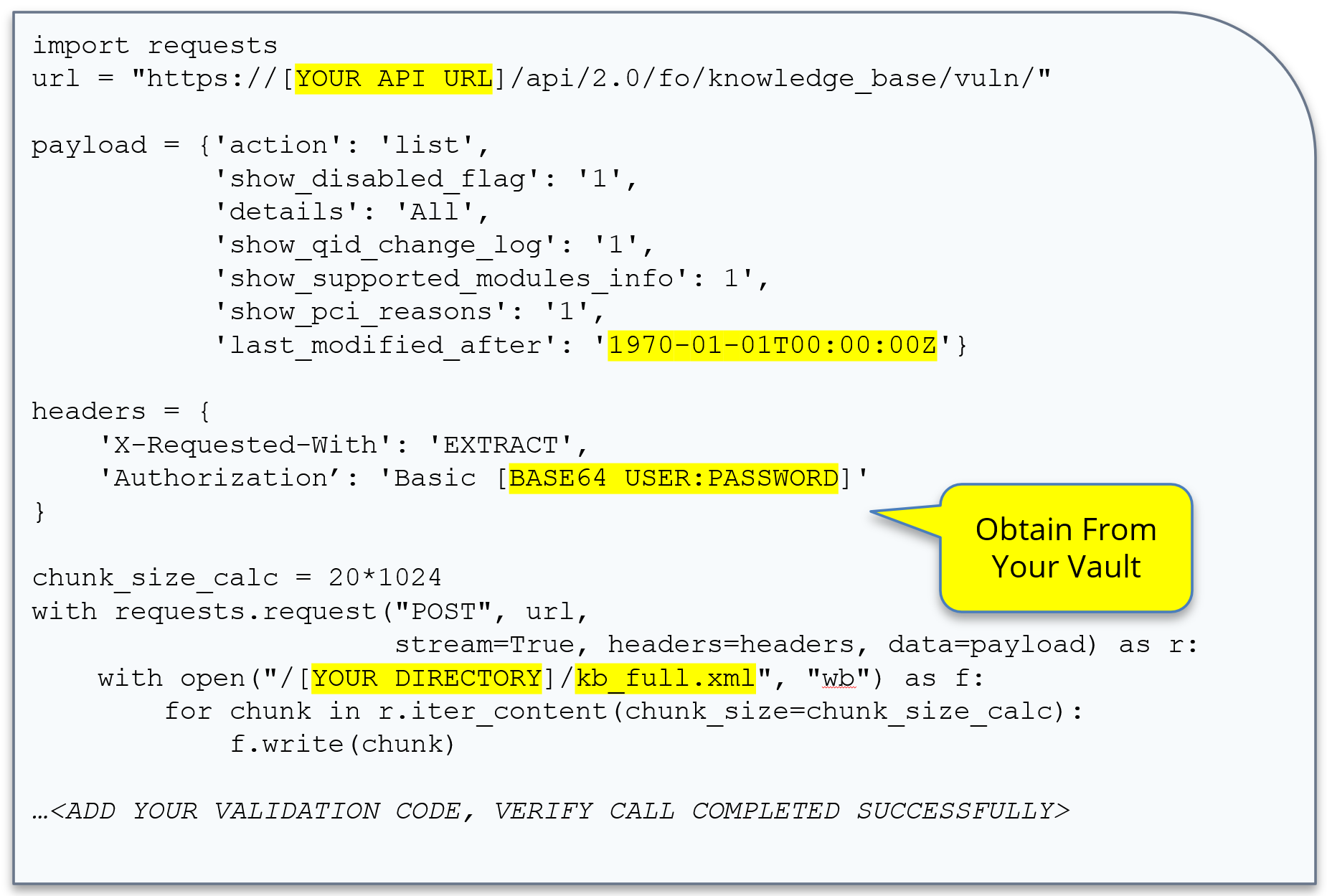
Code Example 1: Full Extract
This example code shows how to stream the full KnowledgeBase to a file. The size of the full KnowledgeBase is around 2-300 Megabytes when downloaded and varies as QIDs evolve. A QID (Qualys ID) is a Qualys detection. It is the code that is used to detect a vulnerability on your system, and it evolves over time. The QID is a unique key. As you can see, the number of lines of code is quite small. See this code run in the accompanying video.
Three Key Elements of the Qualys KnowledgeBase
This is a snippet of KnowledgeBase XML highlighting three key elements. Note that the QID is the unique key for the KnowledgeBase. Published date and modified date help you to determine when a QID became available for use, and the modified date tells you that the QID has been updated.
Key Elements:
- QID: the unique key for the KnowledgeBase
- PUBLISHED_DATETIME: the UTC datetime when the QID was published for use
- LAST_SERVICE_MODIFICATION_DATETIME: the UTC datetime when the QID was last updated

Code Example 2: Incremental Extract
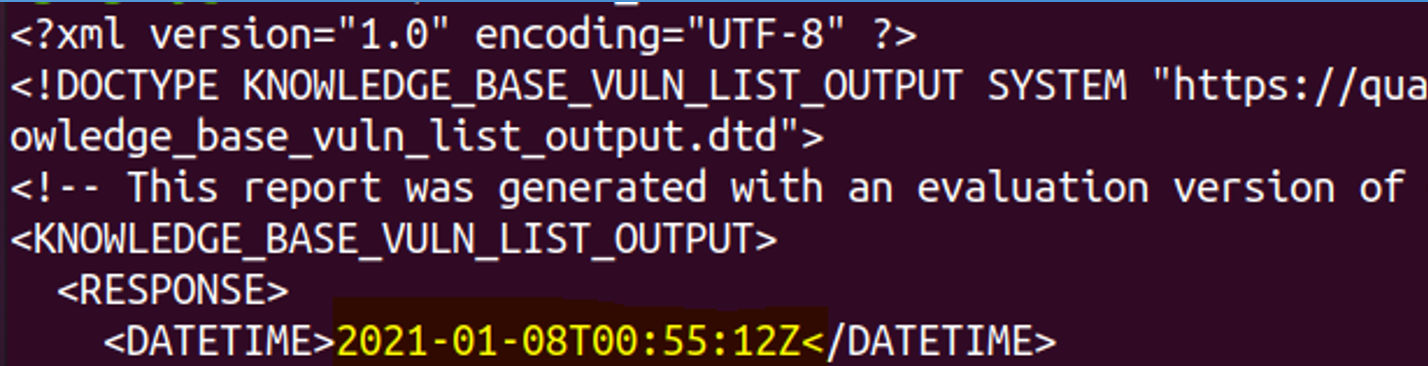
Code example 2 is the exact same code we ran earlier with one key difference: the date of last run. A best practice is to capture the date of the previous run, found in the XML, and use that as a starting point for your next incremental run.
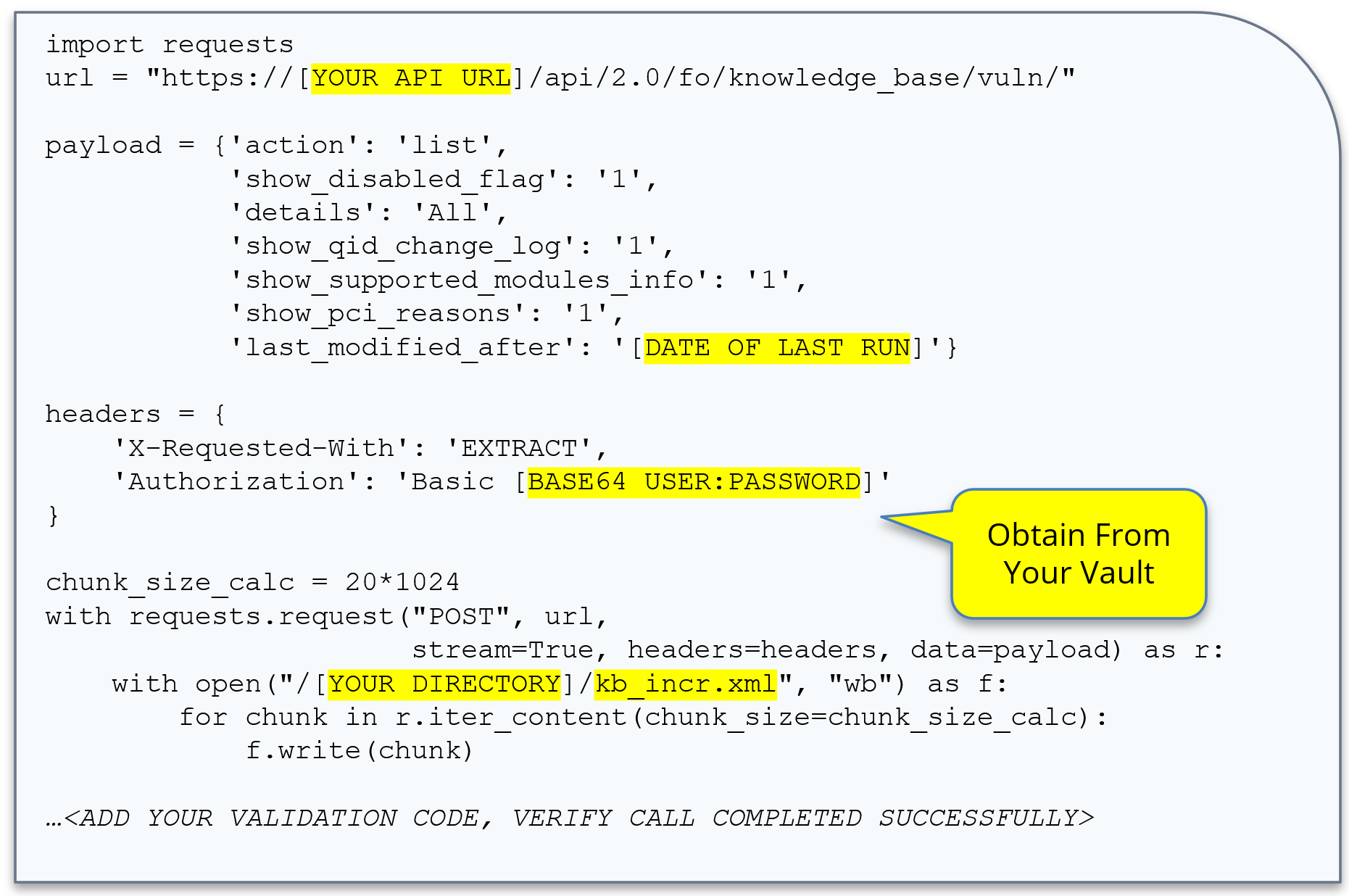
See this code run in the accompanying video.
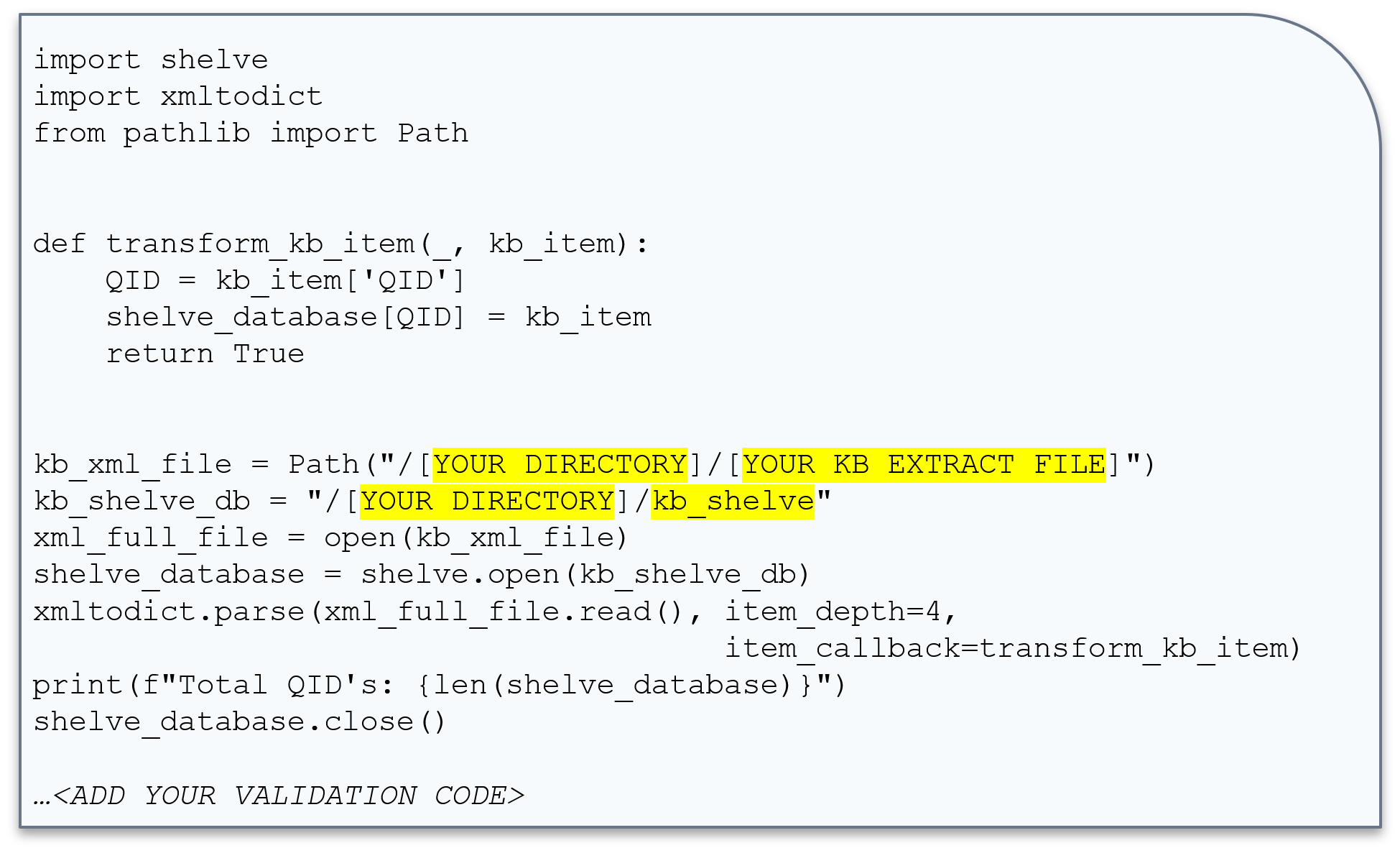
Code Example 3: Transform / Load
Once you have the XML downloaded, you can easily transform the XML into a persistent Python Shelve dictionary. In this case the key to the dictionary is the QID, which is unique. The object stored in the dictionary is the fully nested XML Data Structure that has been converted to a Python Dictionary.
Transform and Load:
- Transform XML to Python Dictionary.
- Load to Python Dictionary to Persistent Shelve DB.
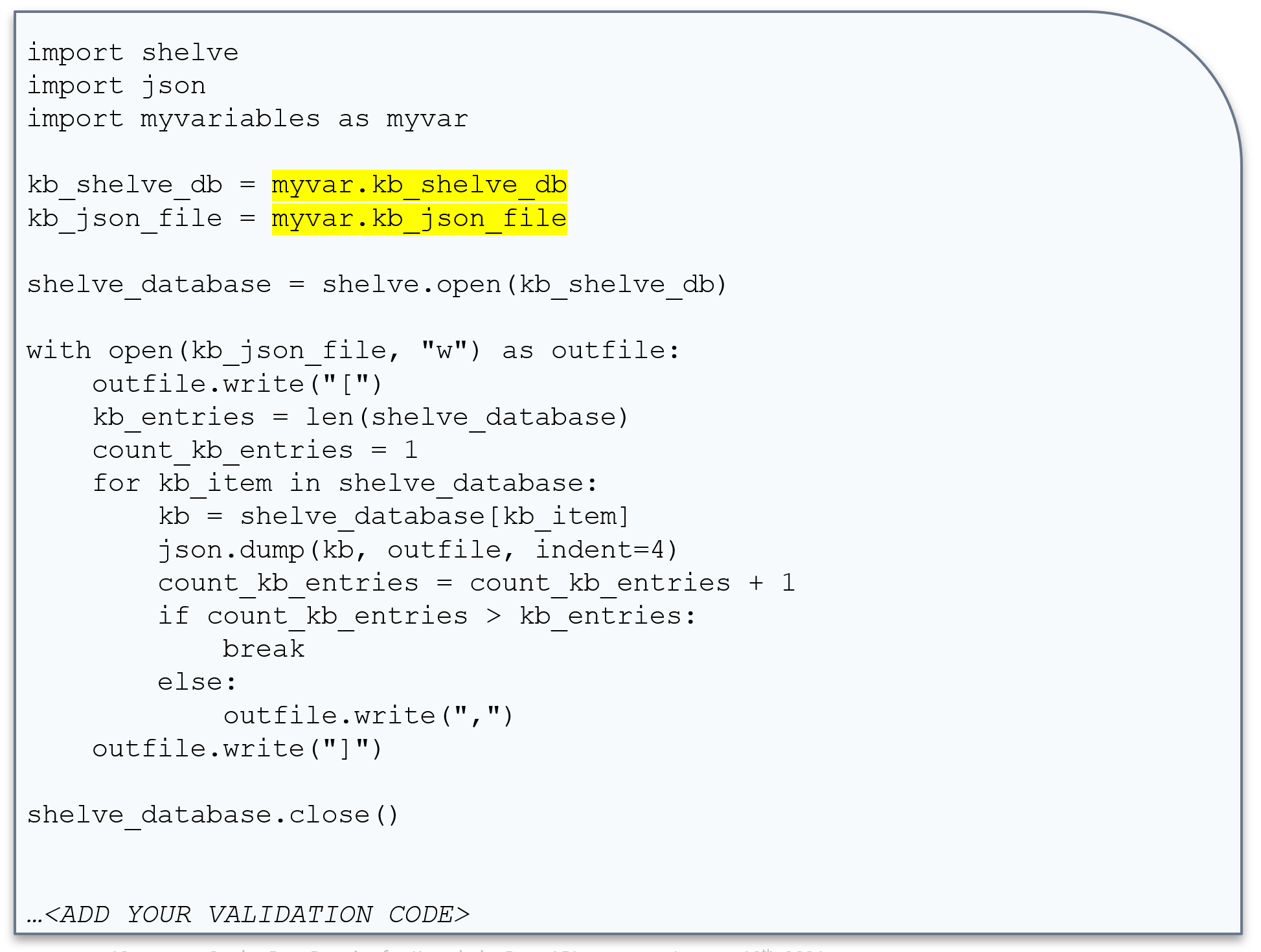
Code Example 4: Transform Python Shelve to JSON
In this final example, we take the Python Shelve Dictionary that was created in the previous example and transform it to output JSON. The input/output are highlighted in yellow. Here we iterate using a for loop to transform each KnowledgeBase entry into a JSON array.
Healthy vs. Unhealthy API Usage
Healthy vs. Unhealthy refers to metrics that help you identify where to improve consumption of CPU, memory, network and disk associated with the KnowledgeBase API.
Healthy – Incremental, Limited Duplicate Data
- ~300-600 API calls per month, 10-20 per day
- ~1-2 gigabyte download per month
Unhealthy – Excessive Full Duplicate Data
- Exceeding 24 API calls per day
- Exceeding 2 gigabytes per month
Determining Health
- Utilize your Activity Log in Qualys to review the number of calls you are making to the KnowledgeBase API.
- Your TAM (Technical Account Manager) can setup a call with a Solutions Architect to deep dive and understand which of your Qualys API IDs are applying best practices for KnowledgeBase consumption.
Put it into Practice
Going forward, here are some final key tips:
- Use ETL design pattern to consume KnowledgeBase API data
- Optimize your KnowledgeBase API calls by using incremental updates.
- For questions, schedule time through your TAM to meet with our solutions architects, we are here to help.
Learn More
- Video: API Best Practices Part 1: KnowledgeBase API
- KnowledgeBase API Guide within VM/PC Guide
- QID Search and Descriptions
- Vulnerability Detection Pipeline
- Qualys API Training (Including Postman)
About This Series
The API Best Practices Series is designed for stakeholders or programmers with general knowledge of programming who want to implement best practices to improve development, design, and performance of their programs that use the Qualys API.
The series will expand over the coming months to cover other key aspects of the Qualys API, with each presentation building on the previous one and in aggregate providing an overall best practice view of the Qualys API. The next presentations in the series will focus on Host List, Asset Group List, and Host List Detection APIs.
David, thanks for sharing this.
I am currently developing a simple set of tools using Excel/Power BI to contact the KB database.
All works great and I’ve improved local performance by filtering only the QID’s found in the scan this month which means the local KB database is reduced significantly.
One issue I am finding though is when trying to download the CVE’s associated with each QID. This takes a long time and is presented row by row for each CVE to each multiple QID. When downloading a report direct from the service, the CVEs are listed in a comma separated fashion in a single field. Is there a way to get the data extracted this way using power query or do I just need to download then transform data locally?
Hi David, excellent read!
I was curious how you came up with the Heathy/Unhealthy API Usage and where those numbers come from. Its seems unusual to say that making more than 1 request/hour/day would be excessive.
Curious to hear your thoughts.