Automatic vs. Manual Data

“You know only insofar as you can measure.”
– Lord Kelvin
“If you want it, measure it. If you can’t measure it, forget it.”
– Peter Drucker
Measurement is critical in achieving objectives. But a more subtle factor drives your success: what you measure and how you measure it. These are what guide your actions. The measurement of vulnerabilities is no exception, and with vulnerabilities, the difference between automatic and manual data and its implications are the key factors.
So, what is the difference?
Manual data is a point-in-time snapshot of vulnerability data that is tied to a single scan and shows the vulnerability posture of the hosts at the time the scan was run.
Automatic data is data from multiple scans normalized into a database. It is the asset-centric history of vulnerability data, built out of the results of previous scans.
Simple enough, right? Let’s examine the implications.
Assessment vs. Management
Manual data lets you assess vulnerabilities, but you need automatic data for vulnerability management.
Manual data shows you where you’re vulnerable at the time of the scan. You can think of manual data as a file folder on the left side of your desk with a folder corresponding to each scan. Inside each folder is a piece of paper containing the forensic record of the raw results from that point-in-time scan. The biggest limitation of this data model is that it lacks context and trending since it is a snapshot of a point in time. For example, if you scanned on January 1 and found 500 vulnerabilities, then scanned the same assets on February 1 and found 300 vulnerabilities, what does that mean? Did you fix all 500 vulnerabilities from January and have 300 new vulnerabilities for February? Did you fix 200 vulnerabilities from January and have 300 left, but no new vulnerabilities in February? There are several other potential scenarios that would also need to be considered, and determining the answer with any degree of certainty is problematic at best.
If you only have access to manual data, you have to perform a manual monthly process with a custom spreadsheet to attempt to reconcile and normalize the results from scan to scan to show month-over-month trending.
Another big problem with this data model is that it is difficult to track the lifecycle of a vulnerability on a particular host. For example, you should be careful not to assume that if you don’t find a vulnerability in a subsequent scan that it has been fixed. This is a poor assumption as there is a huge difference between "fixed" and "not found". For example, if you first scan with authentication, then scan without authentication, many vulnerabilities won’t be detected in the second scan, simply because authentication wasn’t used. This does not mean that the vulnerabilities are actually fixed and can lead to a false sense of security.
Lifecycle of a Vulnerability
Automatic data addresses these limitations by introducing the concept of a vulnerability’s state and providing additional context that is valuable when managing the lifecycle. Automatic data can be thought of as a large relational database on the right side of your desk that normalizes the results of every scan over time for each asset. A vulnerability can have one of four states:
- NEW: Detected for the first time
- ACTIVE: Detected more than once
- FIXED: Detected, then confirmed to be resolved by scanning in the *same* manner as originally detected – e.g. with authentication
- REOPENED: Detected, confirmed to be remediated, then detected again. This may be the result of a machine being re-imaged without all relevant patches being applied.
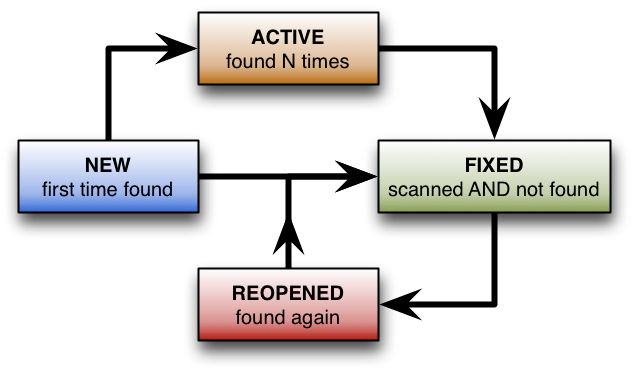
The automatic data also enable users with the capability to mark vulnerabilities as IGNORED, and create an audit trail of all the transitions. The IGNORED state is complementary to the status. A vulnerability can be NEW/IGNORED or ACTIVE/IGNORED for instance. It is a way to manage exceptions.
Trending and Reporting
In addition to a vulnerability’s state, automatic data allows us to report on when a vulnerability was first detected, last detected, and the number of times it has been detected. Also, vulnerability status is tracked intelligently to account for different option profiles being used. For example, if a vulnerability is first detected using authentication, it will not be considered closed until a rescan *with authentication* confirms that the vulnerability has been resolved. This addresses the limitation of the assumption that not found = fixed. And it prevents "saw tooth" trend results that can happen when scans are conducted with varying configurations (e.g. with / without authentication) over time.
This type of accurate trending information is valuable to be able to correctly report the postures of organizations and the progress (or lack thereof) over time in remediating vulnerabilities in their environments. Using the QualysGuard Detection API, this concept of vulnerability state/trend information can be included in data integrated with third party platforms (e.g. SIEM, GRC, etc). Without automatic data, organizations are left to extremely manual, time-consuming, and error-prone approaches to attempt to measure and track the effectiveness of their vulnerability management programs over time.
Decoupling Reporting / Remediation from Scanning
One other main benefit of automatic data is that it allows the scanning and reporting/remediation efforts to be decoupled since all the data is tracked and normalized. Scanning can be conducted according to location and reporting can be performed according to those responsible for remediation.
User Interface
The most obvious place where the difference between manual and automatic data is found in the QualysGuard user interface is when editing a scan report template and choosing the Scan Results Selection:
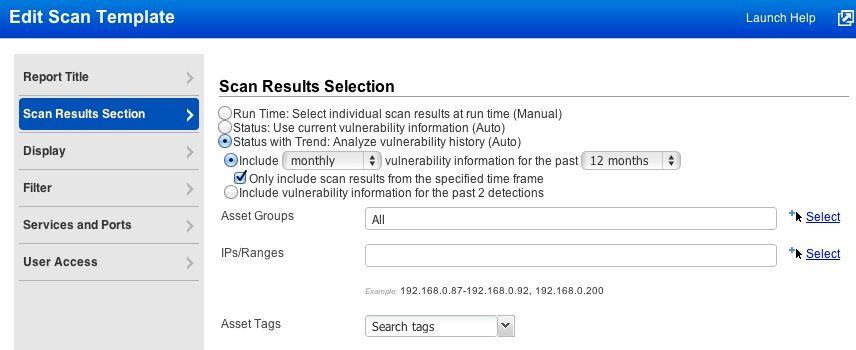
Automatic data is also used in “Status” and “Status with Trend” scan reports and Scorecard reports, as well as throughout the user interface including your dashboard, asset search results, remediation tickets and host information.
Automatic is the Way to Go
The difference between manual and automatic data is the difference between a vulnerability assessment program that identifies only current vulnerabilities and a vulnerability management program that drives the remediation of vulnerabilities over time. Automatic data makes QualysGuard the only vulnerability management solution that can differentiate between vulnerabilities that are actually fixed, versus those that simply weren’t detected.
Contributors to this article: Jason Falciola, Steve Ouzman, Karl G. Schrade, and Leif Kremkow.