From Patching to Eliminating Risk: What’s new in TruRisk™ Eliminate and Patch Management

As IT and security priorities converge under rising pressure, patch management is no longer just a hygiene activity but a strategic tool to eliminate the risk from exposed vulnerabilities. Since the last major release cycle, we’ve been expanding the Qualys Patch Management solution into a broader capability. These enhancements span the architecture, automation, and risk-based prioritization, reflecting a deliberate shift from reactive patching to intelligent, outcome-driven remediation.
Patch management is no longer confined to scheduled maintenance windows. It’s now a critical lever for strengthening security posture, mitigating risk, and ensuring operational continuity. In this blog, we’ll explore how these updates help both SecOps and IT Operations teams drive more effective, scalable remediation, backed by real-world use cases that enhance organizational resilience.
Let’s dive into the latest capabilities added to the platform.
For SecOps: Proactive Risk Reduction and Security Governance
SecOps teams are constantly working to reduce time-to-remediation and manage risk exposure. Qualys’ new capabilities help address these priorities by giving security professionals direct control over the risk mitigation and gives more transparency into remediation success.
Eliminations Workflow from VMDR Prioritization Tab (Release 3.6)
Security teams can now launch the Eliminations workflow directly from the VMDR Prioritization tab, enabling them to apply mitigation actions—such as disabling services or ports—across a large number of vulnerable assets grouped by QID, even when no patch is available. This marks a significant improvement over the previous limit of 200 assets via the Vulnerabilities tab.
Additionally, platform-specific workflows are automatically separated when the same QID affects multiple OS types.
Why It Matters:
1. SecOps can now act at scale to reduce risk quickly during zero-day events or unpatched vulnerability windows—covering more assets, more efficiently.
2. IT Ops benefits from a more streamlined job creation process across heterogeneous environments.
Application from the Eliminations Tab (Release 3.0)
Now, security teams can deploy the mitigation scripts (like disabling services or ports, modifying registry keys) when patches are unavailable to reduce the risk exposed.
This is very critical when a zero-day vulnerability is disclosed and no official patch exists, SecOps can act immediately to reduce exposure.
Why It Matters: Rapid response is possible during critical vulnerability windows.
Mitigation Rollback (Release 3.2)
If required in the future, you can roll back the security mitigation actions in case you don’t need them. This may be due to the availability of patches for the same vulnerability for which a patch has been applied.
Why It Matters: Allows you to balance security urgency with operational safety.
Isolate with Rollback (Release 3.2)
Now you can contain the risk associated with a high-risk zero-day vulnerability even when no patch or mitigation is available. You can isolate the affected asset with only the minimum required access, allowing you to apply a patch or mitigation later. Once the vulnerability is remediated, you can roll back the isolation task to return the asset to the network.
Why It Matters: This allows you to be assured when you have zero-day vulnerabilities or when a patch for a critical vulnerability needs to be rolled back due to known issues.
For IT Operations: Streamlined Execution and System Stability
For IT Operations, Qualys Patch Management now empowers teams to balance uptime, consistency, and modernization through intelligent automation features.
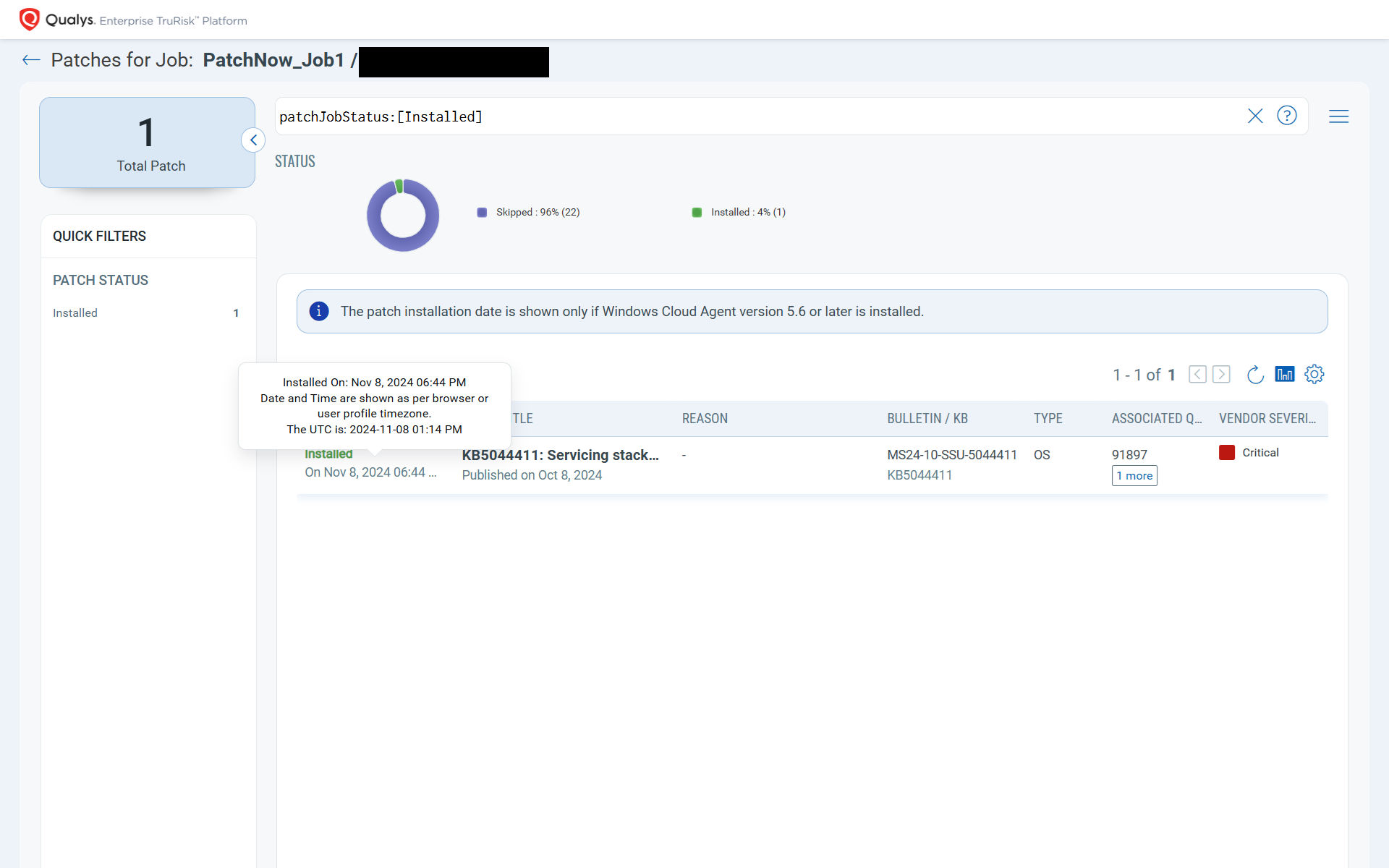
Installation Visibility with Patch Installation Date (Release 2.11)
You can now easily track when a patch was applied, using the date, and validate it for policy compliance. This allows you to quickly demonstrate patch timelines for critical CVEs during an audit.
Why It Matters: It aids in security governance and regulatory needs.
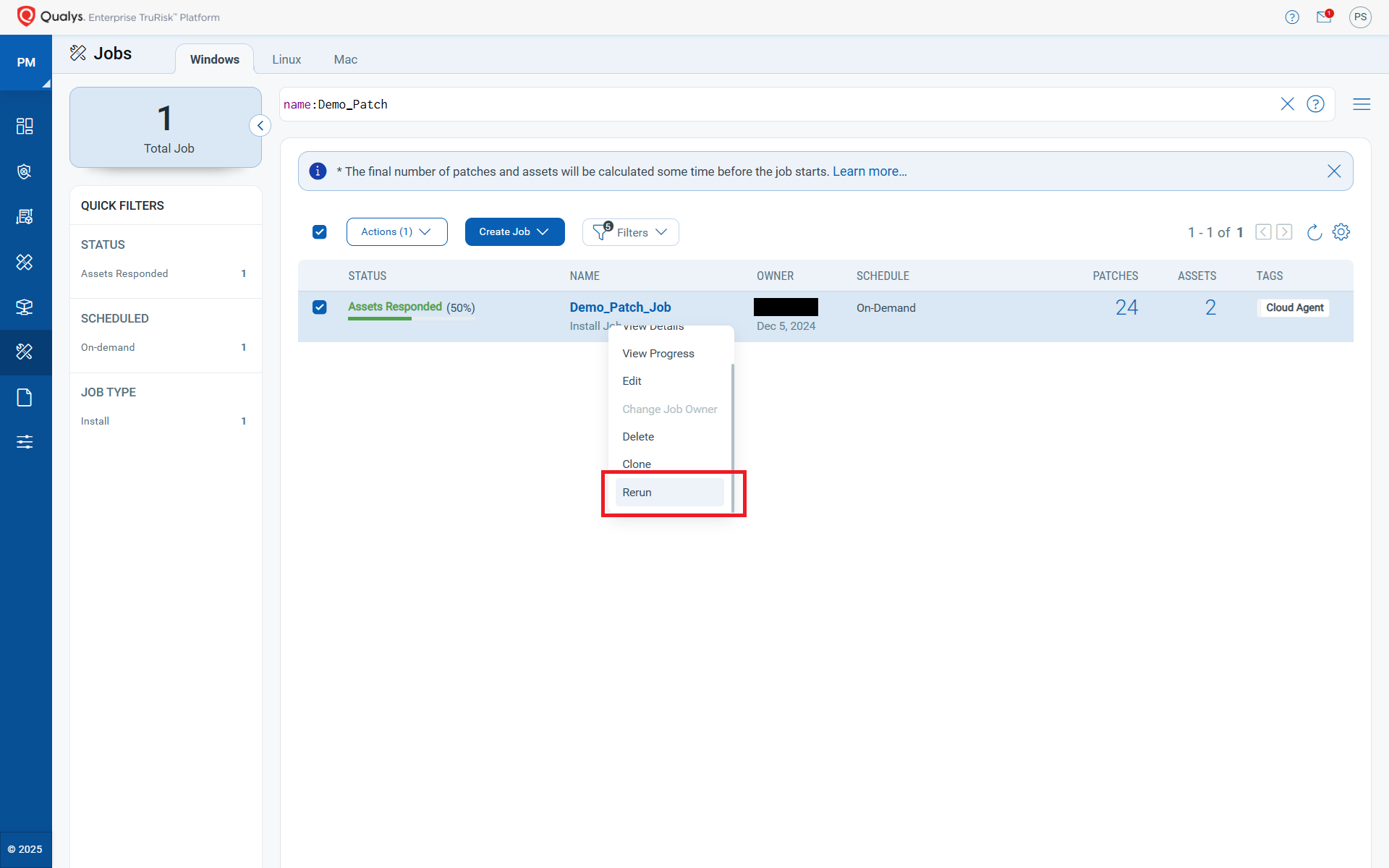
On-Demand Job Rerun and Edit (Release 3.0)
The Edit and Rerun feature helps improve patching compliance by addressing failures or misconfigurations, without the need to start job creation from scratch. In dynamic IT environments, failures can result from something as simple as an overlooked IP range or a last-minute change in scope. Instead of rebuilding entire jobs, you can now make quick adjustments: modify configurations, update asset scopes by including or excluding appropriate tags, or tweak job options—then simply rerun the job with these updates.
Why It Matters: It minimizes the operational overhead, especially during high-pressure windows like critical patching weekends or zero-day responses. It also helps in creation of lesser Jobs to maintain if you have a way to apply incremental patches. Edit and Rerun can also be used for Cluster Servers Patching if you have a proper tagging of the assets in place.
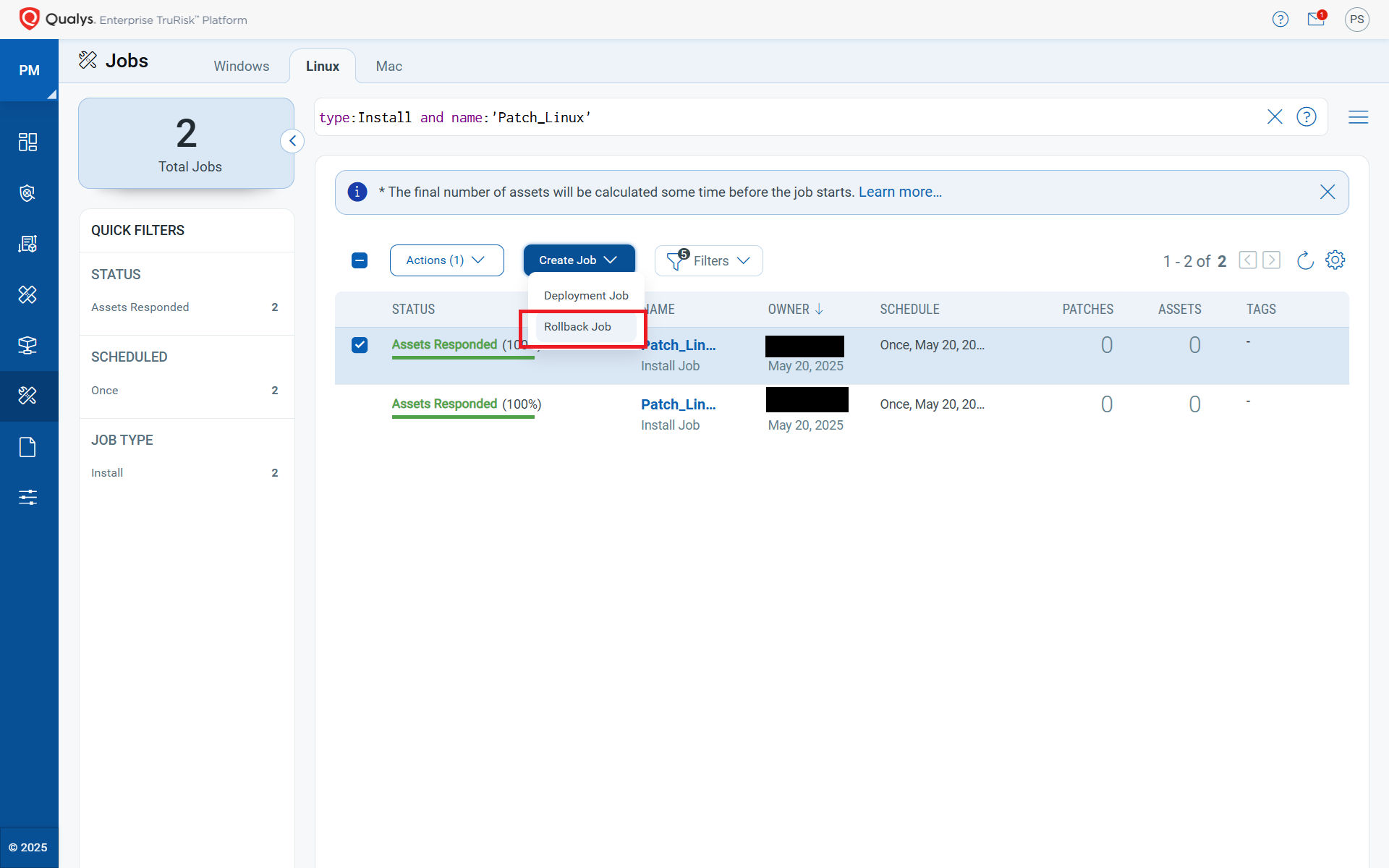
Rollback Jobs on Linux (Release 3.3)
A security patch may cause performance degradation in production, and at times, a rollback may be the only viable option. This feature provides IT Operations with a powerful safety net by allowing systems to be reverted to their previous state if a patch introduces instability or breaks functionality. This is especially critical in production environments, where even well-tested patches can lead to unexpected performance issues, application conflicts, or service disruptions. With rollback capability now available for Linux (already supported on Windows), teams no longer need to rely on time-consuming system restores.
Why It Matters: This minimizes potential disruption to high availability. The IT Operations team can quickly undo changes that would otherwise take days—or even weeks—if they had to manually uninstall patches from all servers. Imagine the pain teams currently endure without this capability: logging into individual machines, determining their previous state, and manually restoring each one.
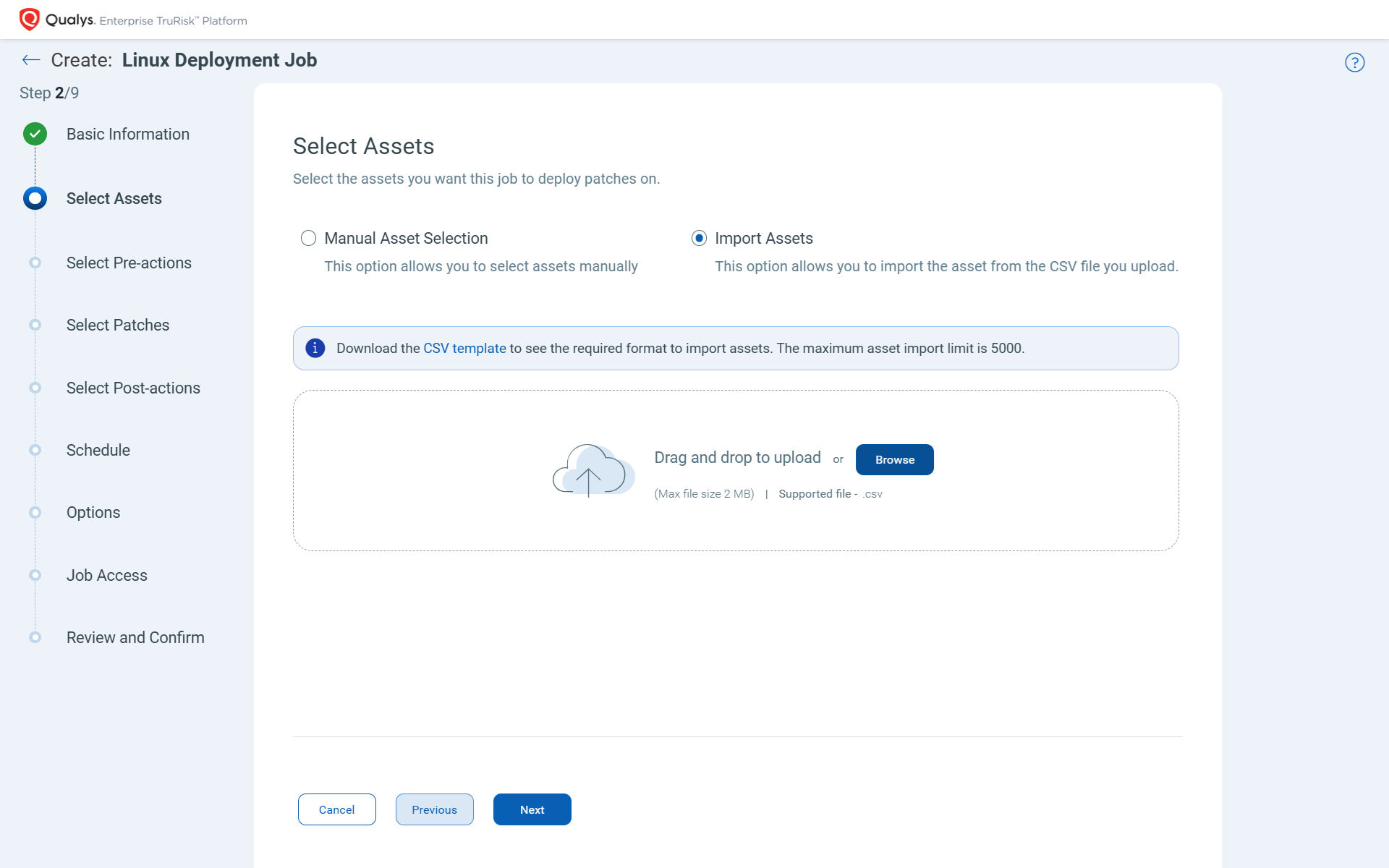
CSV Asset Import in Jobs (Release 2.12)
You’ve identified the assets that likely don’t have a single tag. The best approach is to maintain a list and apply patches directly to those identified assets. Don’t spend time searching and tagging them during the job creation process. Instead, quickly define patch scopes using a static list of assets. A quick export from a CMDB or asset inventory can be used to precisely target the machines and imported during job creation.
Why It Matters: It allows you to effectively patch in controlled environments, such as patching a subset of production servers or prioritizing high-risk assets identified during a vulnerability scan. It also reduces the risk of configuration errors and ensures alignment with asset management practices. By selectively importing assets, you minimize the chances of missing or incorrectly including systems, helping you organize and maintain patching accuracy across large or segmented infrastructures.
Unified Reports Tab (Release 2.12)
This feature consolidates visibility across multiple reports, summarizing the outcomes of all patch jobs, patch availability, and asset information into a single, centralized view. You can generate platform-specific reports, customize them, and access detailed information on patch compliance at the asset level.
Why It Matters: All the operational data you need during reporting cycles—such as monthly status meetings or compliance reviews, where quick and accurate insights are essential for informing stakeholders—is now available at a click. Teams can easily identify successes, failures, trends, problematic patches, and asset health, enabling faster decision-making and clearer communication with leadership.
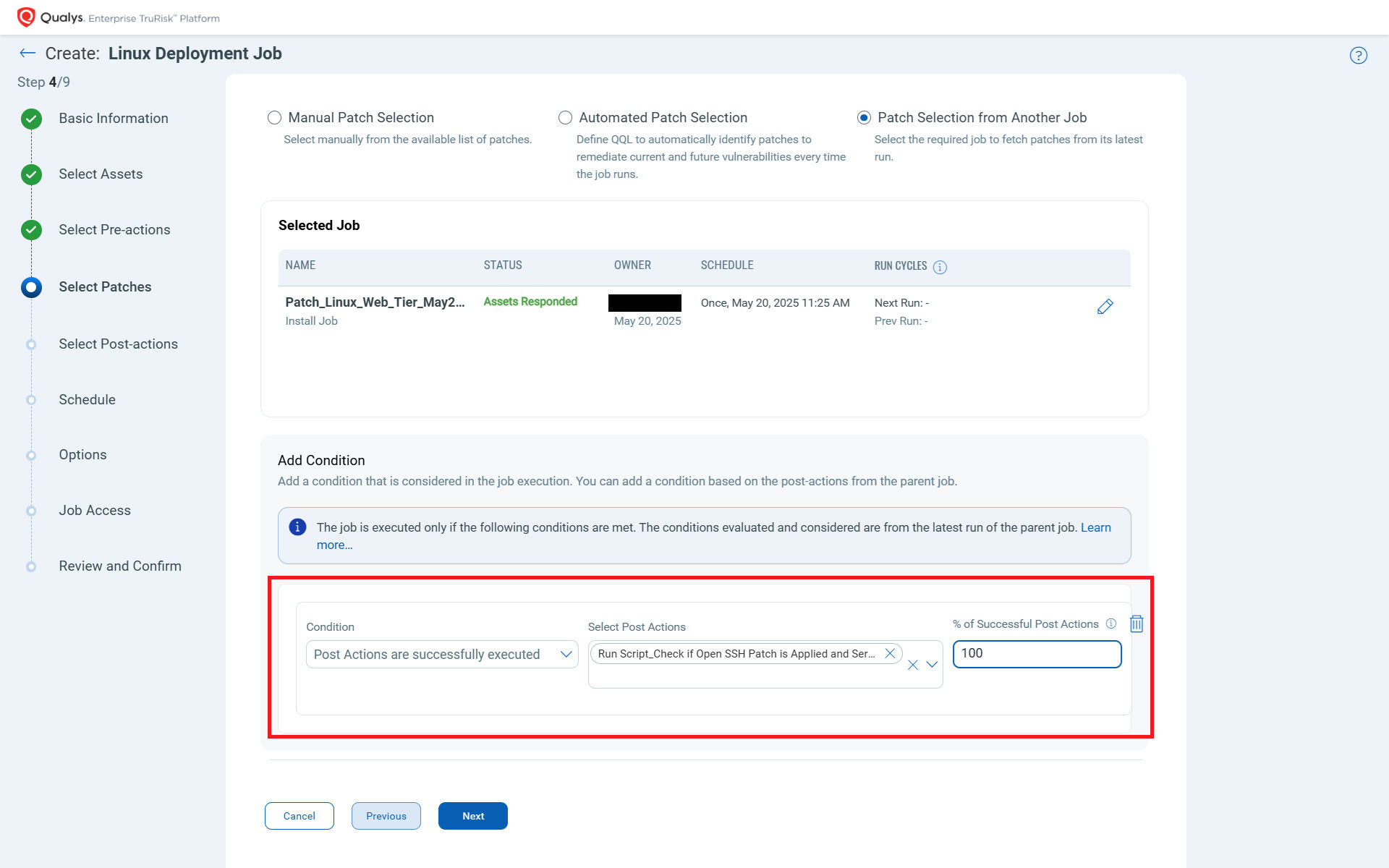
Chaining of Jobs (Release 3.3)
The complexity of patching operations increases when patches must first be tested in staging environments before being applied in production. With Chaining of Jobs in Qualys Patch Management, IT Ops teams can now create tightly sequenced patch jobs, where one job executes only if the previous one completes successfully, based on a success criterion defined in post-actions.
Why It Matters: Consider the checks required after a coordinated sequence of dependent actions—patching, rebooting, validating patch installation, and ensuring a successful restart of business services. This becomes especially critical when patching clustered servers in a round-robin fashion. The successful patching and service restart on one server should be a prerequisite for triggering patching on the next.
Abort a Job before patch is applied based on Pre-conditions (3.3)
The new pre-condition check allows you to abort a job based on readiness criteria you define. For example, you may want to abort a job if a business service is currently running and needs to be brought down before patching a third-party application like MS SQL Server. Another useful scenario is monitoring CPU usage before starting the patching process to ensure it doesn’t impact endpoint performance.
Why it matters: It helps protect the production environment from unintended changes or potential patching failures, such as insufficient disk space or active application usage, that could otherwise lead to disruption.
Additional OS Support
Additional OS version support for different releases improves patching compliance across your environment. Together, these capabilities help IT Ops teams automate confidently across platforms, geographies, and system lifecycles. For the latest snapshot of supported OS versions, please visit: https://success.qualys.com/customersupport/s/cloud-agent-pam
A Glimpse into the Future
Patch management is evolving from a reactive chore into a predictive capability, one that meaningfully connects SecOps priorities with IT execution. It’s no longer about fixing everything; it’s about fixing what matters most. Our goal is to give teams the operational risk insights they need, automate intelligently within existing workflows, and track progress through measurable outcomes. Stay tuned—more updates are on the way.
Curious how this works in your own environment? Try it out and see the impact of prioritized, operationally aligned remediation.